2023 年也是充实的一年。
全民制作人们大家好,又到了一年一度的汇报时间。
账号更名为“霍丙乾 bennyhuo”
年初做了一件比较重要的事情,就是账号更名,主要涉及到以下几个平台:
- Bilibili、YouTube、掘金、抖音等:从 “bennyhuo 不是算命的” 改为 “霍丙乾 bennyhuo”
- 微信公众号:从 “Kotlin” 改为 “霍丙乾 bennyhuo”
这其中涉及到几个小问题,为了不给大家造成困扰,我简单再做下解释。
1. 我的微信公众号为什么叫 “Kotlin”?
2016 年,我注册了一个名为“Kotlin”的微信公众号,用来发布 Kotlin 的推广视频。2020 年前后,JetBrains 开始在国内投入专人负责社区的建设和运营,微信公众号 “Kotlin” 则主要用于转发官方文章。当时我的主要精力 B 站账号的建设上,输出形式也以视频为主。2023 年,有一些朋友问我为什么视频不发公众号,因为我很少会将与 Kotlin 无关的视频同步到微信公众号 “Kotlin” 上。
思考再三,我跟 JetBrains 的朋友提了一下我的想法:我们可能需要一个真正意义上的 Kotlin 官方号。这就是我的所有账号更名的由来。
如果大家希望持续关注 Kotlin 的发展,强烈建议大家关注官方微信公众号 Kotlin 开发者。
如果你平常也喜欢在 Bilibili 上看视频,也建议关注 JetBrains 的官方账号 JetBrains中国:
我个人也会持续关注 Kotlin 的发展,并且在 Kotlin 发布新版本之后,也会以视频的形式为大家介绍其中的新特性。
2. 为什么不统一更名为 “bennyhuo 不是算命的”?
我最初确实想统一成 “bennyhuo 不是算命的”,但微信公众号的名称中禁止出现“算命”,因此只好再选一个名字。想来想去,干脆用自己的真名好了,省事儿。
顺便提一句,“bennyhuo” 是我在腾讯打工的时候的“代号”。
视频内容
今年在 B 站、YouTube、抖音、微信公众号同步发视频,欢迎在你喜欢的平台搜索:霍丙乾 bennyhuo 并持续关注。
其中,B 站仍然是我视频发布的最主要的平台。2023 年全年发布视频 127 个,总计播放 60 万次。其中,所有视频累计播放在 6 月份突破了 100 万次,单稿播放最高纪录靠鸿蒙刷到了 7 万+。订阅量从年初的 17500 左右增长到接近 23500,平均每天净增长 15,谢谢大家的关注和一键三连。
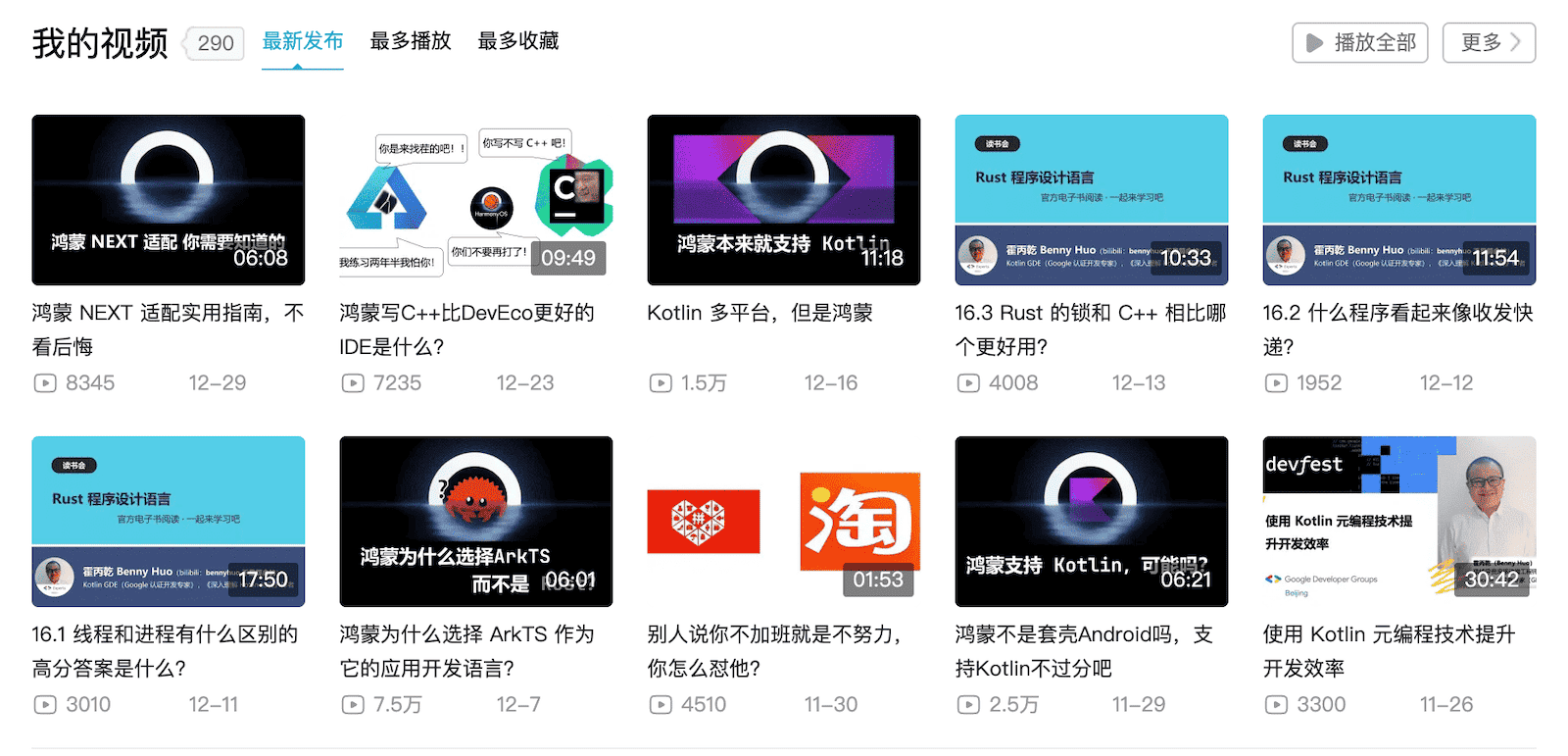
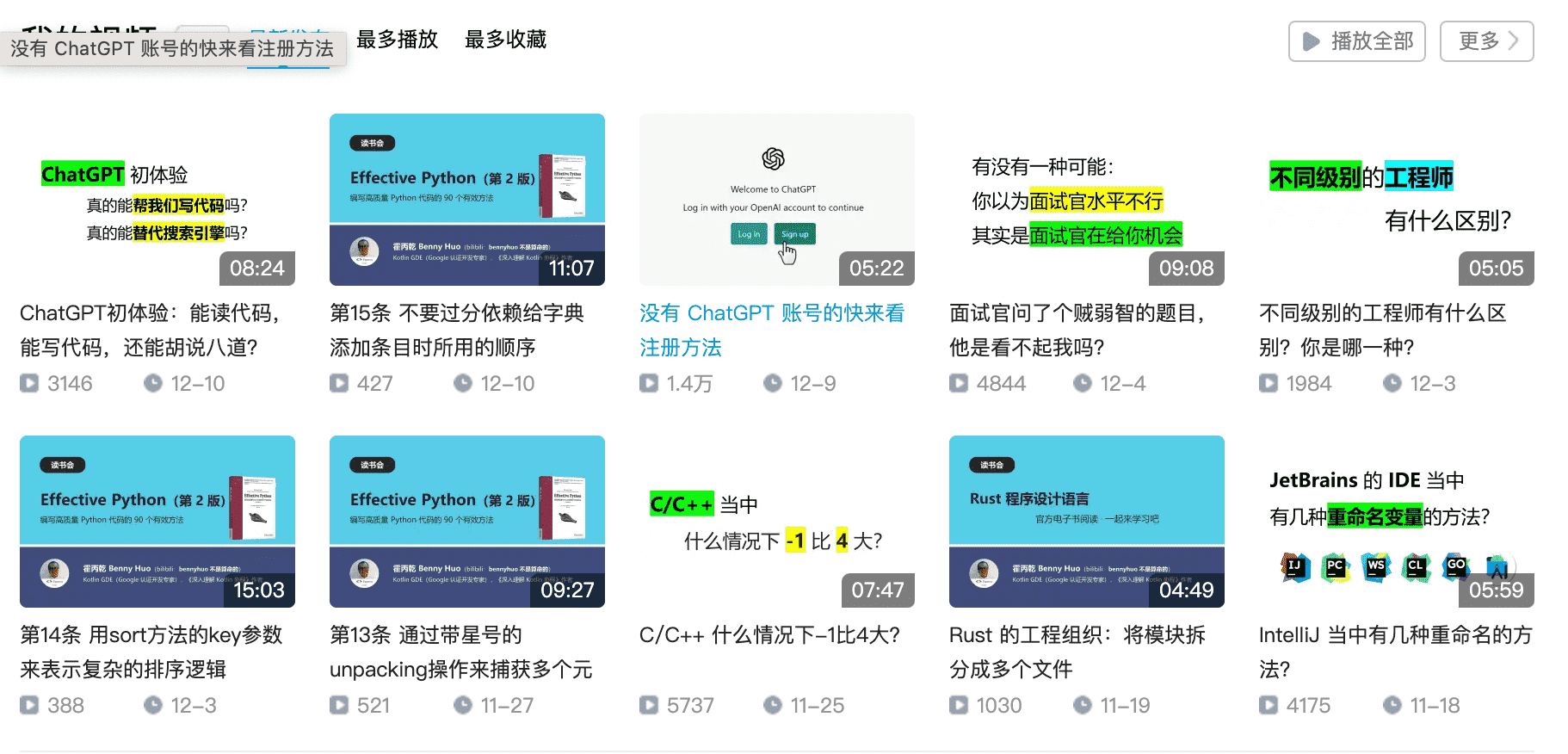
2023 年的视频仍然以读书视频为主。
此外,还有一些编程语言版本新特性的视频:
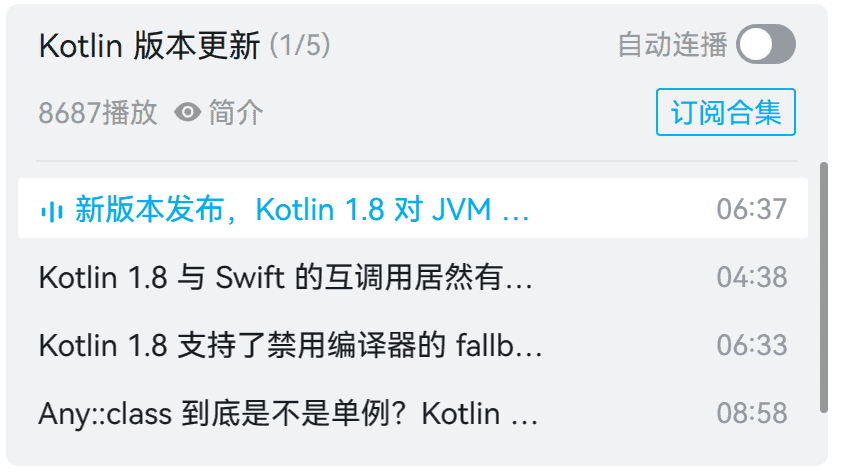
- Kotlin 版本更新的视频:
- Java 版本更新的视频:
年底的时候新开鸿蒙的坑,共计发布视频 6 个:

2024 年计划将《Rust 程序设计语言》按照现在的形式继续更完。而《现代 C++ 特性解析》《Java 核心技术》就不再按照现有的形式继续读下去了,因为这几本书的内容都很多,想要更完并不容易。C++ 和 Java 相关的视频将会参考这些书籍,以一种更加紧凑的形式更新下去。至于为什么要坚持更完 Rust 那本,显然,它最简单,内容也最少。
后面会有鸿蒙开发教程吗?答案是:不会。成体系的内容做起来费时费力,时间精力跟不上。不过,不出意外的话,我大概率会在 2024 年投入很大的精力参与鸿蒙 NEXT 的适配工作,因此遇到一些有意思的内容还是会不断与大家分享的。
还会开新坑吗?答案是:可能会有,但可能不会有类似于 Rust 读书这种成体系的视频了。因为我自己的想法天天变,也实在是不太想被自己挖的坑束缚了。
其实核心就一个:更新视频是一件令人开心的事儿,它不能成为我的负担。
文字内容
今年文章写得不多,笑死,因为根本就没写。

好消息是 《深入实践 Kotlin 元编程》 在 2023 年 8 月出版了。这是我的第二本书,内容有一定的难度,适合有进阶需求的 Kotlin 开发者。

社区活动
今年的社区活动,一共有八次,分享了六个不同的主题。其中线上活动五次,线下活动三次。顺便提一句,12 月参加完天津 GDG 的活动之后自驾去海边吹冷风,特别爽。
- 2023.12 机械工业出版社: 我们对 Java 有哪些常见的误区?
- 2023.11、12 GDG DevFest: 使用 Kotlin 元编程技术提升开发效率
- 2023.09 JetBrains 码上道: Kotlin 开发者的首“锈”:Rust 到底香不香?
- 2023.05、06 Java 核心技术大会: Java 的现代化 - 包袱、挑战和革新
- 2023.05 北京 KUG: 你想知道的 Jetpack Compose 的编译器黑魔法
- 2023.04 GDG 社区说: 如何开发一款 Kotlin 编译器插件?

在天津 GDG 的活动上,有位现场的朋友提问,K2 编译器中还会有 PSI 吗?我当时一时没有反应过来,就说回去查证一下再来答复,结果忘了留他的联系方式,只好在这里做一下回答。
其实 FIR 的所有语法节点都有一个 source 的字段用来获取原始的 PSI,如果我们想要分析代码的注释,还是需要通过 PSI 来获取的。所以 PSI 不能说完全去掉了,只是被降级了。
开源项目
2023 年在开源项目上的投入不大,主要还是以维护之前的项目为主。
其中新开源项目 kanyun-inc/Kudos,解决了 Gson 等 JSON 框架在反序列化时不支持 Kotlin 类型空安全、构造器参数默认值等问题。
最近在适配鸿蒙时,还尝试为 Ktor 提供了鸿蒙的 Client 实现,参见:kotlin-for-ohos/ktor。
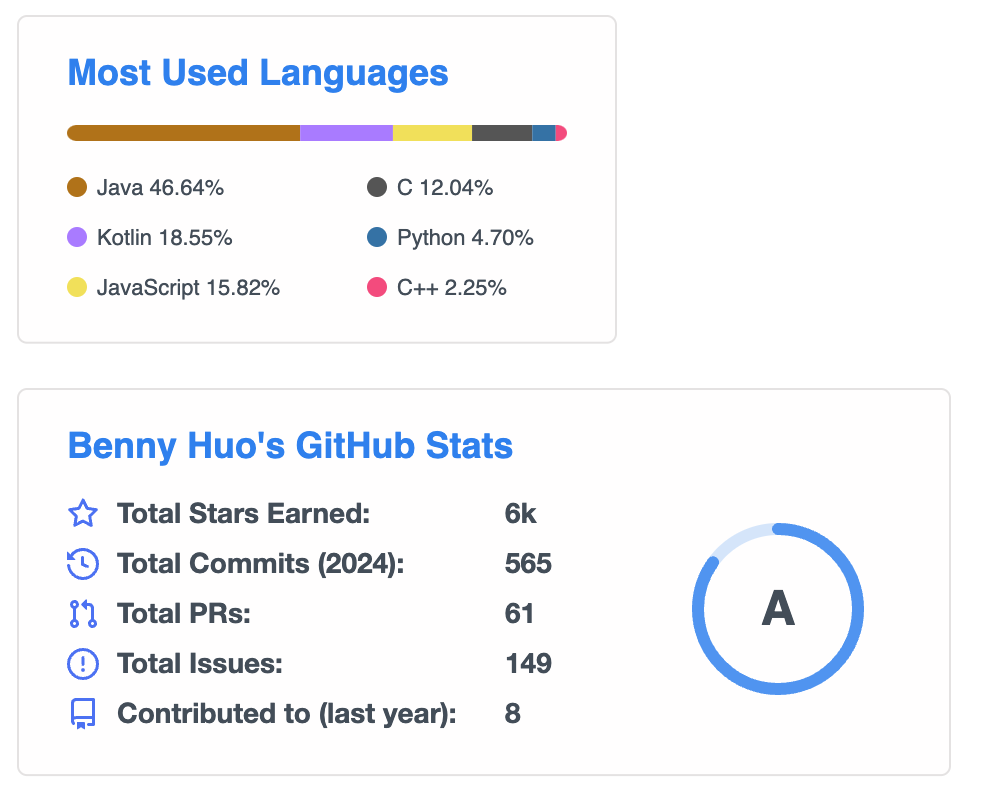
全年的统计数据可以参考:
知识星球
知识星球试运营一年,发布了一些会员视频,包括:
- 《深入实践 Kotlin 元编程》的读书视频,共 12 期
- 会员月刊 共 13 期
之前想开个新栏目,会员朋友们建议更新一些 LeetCode 的刷题视频。结果因为年底事儿太多,一直拖更,隔壁 AB 老师都已经更到停更了,我还没开始。这个专栏争取要在 2024 年更起来。
感谢各位星球会员朋友们的支持。
初心与愿景
为什么做技术分享
十多年前,我刚开始学习编程的时候,网传的各类视频教程给予了我非常大的帮助。我并不是天赋型选手,花了很长时间才学会如何通过翻阅文档和源码来学习新知识。正因为如此,我觉得技术分享是非常有意义的,对于一部分人来说会有很大的帮助。
当然,做技术分享也是有很多好处的,我自己也非常乐于分享。
- 对于一个几乎没有社交活动的人来说,做技术分享是我认识一些很纯粹的朋友的重要渠道。
- 做技术分享还可以不断让自己反复对知识进行求证,反复摔打自己的知识体系,促进自己的技术成长。
- 做分享还可以锻炼自己的表达能力,让自己逐渐适应更大的舞台。
- 做分享可以提升自己的影响力,这实际上也是一种非常奇妙的体验。

因此,我也非常建议大家尝试一下做一些分享,这仍然是一个自媒体的时代,镜头和舞台可以给到每一个人。
什么时候开始“恰饭”?
我看视频评论的时候遇到好几次,“听声音好熟悉,跟慕课网讲 C 语言的老师是同一个人吗” 的疑问。其实之前我在慕课网发布过几门课程,不过因为个人精力和身体原因,我已经决定不再慕课网继续发布新课了。

说起来,今年还花时间更新了一下 C 语言课,优化了一下视频的内容,增加了常见问题的答疑,之前学习过这门课的朋友可以回去看一下更新的内容是否有帮助。

如果有朋友有兴趣在慕课网做讲师,我可以帮忙推荐给慕课网。
说回 B 站,我在 2023 年把视频的收益关掉了,因为实在太少了,指望靠这个买 mac studio,我估计差不多都可以买到 M10 MAX 了。
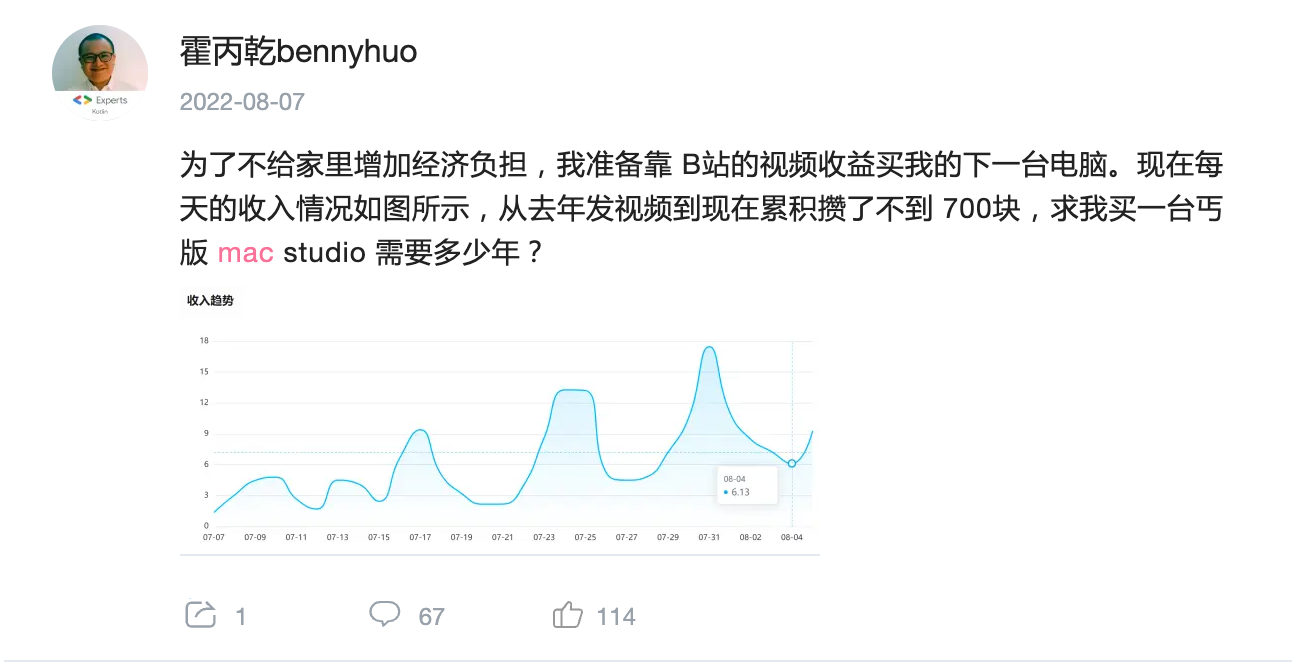
细心的朋友们可能还会发现,我的视频里面几乎都没有明示或暗示过大家投币三连,早期还有一个统一的求关注的结尾,后来我也干脆去掉了。

我希望被更多人关注吗?当然。
我希望我的视频播放量上涨吗?当然。
不过,我更希望我的视频纯粹一些。因此我应该不会在视频里面添加视频内容无关的引导。希望大家通过我的视频有所收获,大家投币点赞也是因为觉得这些视频值得。
至于后面怎么恰饭,如果真的到了需要向生活低头的时候,我大概会把我的知识星球发出来。
微信群群规
为了方便交流,我也拉了一些微信群。熟悉的朋友们知道,我一直坚持要求大家在群里做技术交流,不要高屋建瓴的关心世界,更不要输出负能量。
为什么呢?因为我们的眼界有限,很多见解自以为精妙绝伦,实际上无比稚嫩;退一步讲,就算我们能讨论出有建设性的意见,我们又有什么渠道能够让意见落实呢?更多的,往往是群友们互相断章取义,发展到对人口诛笔伐,最终搞得群里乌烟瘴气。
技术群是为了交流技术,哪怕交流如何跟无良领导作斗争我觉得都可以接受,我甚至会帮忙出出主意,但如果只是想要宣泄不满,建议换个地方。我们都难免遭遇不公,也都难免经历委屈,除非你成为强者,否则谁又愿意听你哭诉呢?

先想办法成为强者,再想怎么改变世界。
最后
希望大家在 2024 年身体健康,工作顺心。
2024 继续加油。
关于作者
霍丙乾 bennyhuo,Google 开发者专家(Kotlin 方向);《深入理解 Kotlin 协程》 作者(机械工业出版社,2020.6);《深入实践 Kotlin 元编程》 作者(机械工业出版社,2023.8);前腾讯高级工程师,现就职于猿辅导
- GitHub:https://github.com/bennyhuo
- 博客:https://www.bennyhuo.com
- bilibili:霍丙乾 bennyhuo
- 微信公众号:霍丙乾 bennyhuo